





La storia dietro Barracuda Active Threat Intelligence
Qualche tempo fa, durante una delle nostre sessioni di brainstorming, mentre i team discutevano del prossimo livello di evoluzione dei nostri prodotti, è diventato evidente che il rilevamento e la protezione contro le minacce nuove ed emergenti richiedevano un'analisi intensiva dei dati su larga scala. L'analisi dovrebbe prevedere il rischio dei clienti e farlo in modo efficiente e rapido, se vogliamo evitare che si verifichino azioni ostili.
Mentre analizzavamo i requisiti, ci siamo resi conto che per proteggerci da hacker avanzati come i bot, dovevamo creare una piattaforma in grado di analizzare il traffico per le sessioni web, correlarlo con i dati tra le sessioni e, per molte cose, nell'intera base clienti. Abbiamo anche capito che molte parti del sistema dovevano essere in tempo reale, alcune quasi in tempo reale, e altre potevano avere una fase di analisi molto più lunga.
Qualche anno fa abbiamo introdotto Barracuda Advanced Threat Protection (BATP) per la protezione dagli attacchi di malware zero-day su tutta la linea di prodotti Barracuda. Questa funzionalità, l'analisi dei file per rilevare il malware utilizzando più motori oltre al sandboxing, è stata introdotta nei prodotti di sicurezza delle applicazioni di Barracuda per proteggere applicazioni come i sistemi di elaborazione degli ordini in cui i file sono stati caricati da terze parti. Questo è stato il primo tentativo di utilizzare un livello basato su cloud per un'analisi avanzata che sarebbe stato difficile da integrare nelle appliance firewall per applicazioni web.
Sebbene il livello cloud di BATP fosse in grado di gestire milioni di scansioni di file, avevamo bisogno di un sistema in grado di archiviare grandi quantità di metadati in modo che potessero essere analizzati per individuare minacce nuove e in evoluzione. Questo ci ha fatto iniziare il percorso verso la prossima piattaforma di intelligence sulle minacce.
Come funziona Active Threat Intelligence
La piattaforma Barracuda Active Threat Intelligence è la nostra risposta. La piattaforma è costruita su un enorme data lake, che può gestire l'elaborazione in streaming e l'elaborazione in batch dei dati. Elabora milioni di eventi al minuto, in tutte le aree geografiche, e fornisce informazioni utili per rilevare bot e attacchi lato client, oltre a fornire informazioni per la protezione da tali vettori di minacce. Barracuda Active Threat Intelligence è costruita con un'architettura aperta per essere in grado di evolversi rapidamente per affrontare le nuove minacce.
Oggi la piattaforma Barracuda Active Threat Intelligence riceve i dati dai motori di sicurezza di Barracuda Web Application Firewall e WAF-as-a-Service, nonché da altre fonti. Man mano che gli eventi vengono ricevuti, vengono arricchiti utilizzando feed di minacce di crowdsourcing e altri database di intelligence. L'analisi dettagliata di questi eventi, sia individualmente che come parte di una sessione utente, viene utilizzata per classificare i clienti come umani o bot.
Le pipeline di analisi dei dati utilizzano vari motori e modelli di machine learning per analizzare più aspetti del traffico e raggiungere le loro raccomandazioni, che vengono infine riconciliate per produrre il verdetto finale.
In che modo Active Threat Intelligence aiuta a proteggere le tue app
Oltre a supportare tutte le analisi richieste per la protezione avanzata dai bot, la piattaforma Active Threat Intelligence viene utilizzata per le nostre ultime offerte: protezione lato client e motore di configurazione automatizzato.
Active Threat Intelligence tiene traccia di tutte le risorse esterne che possono essere utilizzate dall'app, ad esempio un JavaScript esterno o un foglio di stile. Tenere traccia delle risorse esterne ci assicura di essere consapevoli della superficie delle minacce e di poterci proteggere da attacchi come MageCart e altri.
Poiché i metadati raccolti sono estremamente ricchi, siamo in grado di ricavarne informazioni aggiuntive per assistere gli amministratori fornendo consigli di configurazione basati sul traffico reale che arriva alle loro app.
Questa piattaforma è stata fondamentale per aiutarci a creare la prossima generazione di funzionalità di protezione richieste dai nostri clienti. Continuiamo a sfruttare questa piattaforma scalabile per raccogliere informazioni approfondite sui modelli di traffico, sul consumo delle applicazioni e altro ancora. Non perderti i post sul blog dei nostri team di ingegneri che parleranno di come abbiamo sviluppato Barracuda Advanced Threat Intelligence.

Anshuman Singh è Senior Director Product Management presso Barracuda. Entra in contatto con lui su LinkedIn qui.
L'evoluzione della pipeline dei dati
La pipeline di dati è il pilastro centrale delle moderne applicazioni ad alta intensità di dati. Nel primo post di questa serie, daremo un'occhiata alla storia della pipeline di dati e a come queste tecnologie si sono evolute nel tempo. Più avanti descriveremo come stiamo sfruttando alcuni di questi sistemi in Barracuda, gli aspetti da considerare nella valutazione dei componenti della pipeline di dati e nuovi esempi di applicazioni per aiutarti a iniziare a creare e implementare queste tecnologie.

MapReduce
Nel 2004 Jeff Dean e Sanjay Ghemawat di Google hanno pubblicato MapReduce: Simplified Data Processing on Large Clusters. Hanno descritto MapReduce come:
"[...] un modello di programmazione e un'implementazione associata per l'elaborazione e la generazione di set di dati di grandi dimensioni. Gli utenti specificano una funzione di mappatura che elabora una coppia chiave/valore per generare un insieme di coppie chiave/valore intermedie, e una funzione reduce che unisce tutti i valori intermedi associati alla stessa chiave intermedia."
Con il modello MapReduce, sono stati in grado di semplificare il carico di lavoro parallelizzato della generazione dell'indice web di Google. Questo carico di lavoro è stato programmato su un cluster di nodi e ha offerto la possibilità di scalare per tenere il passo con la crescita del web.
Una considerazione importante di MapReduce è come e dove vengono archiviati i dati nel cluster. In Google questo prende il nome di Google File System (GFS). Un'implementazione open source di GFS del progetto Apache Nutch è stata infine trasformata in un'alternativa open source a MapReduce chiamata Hadoop. Hadoop è nato da Yahoo! nel 2006. (Hadoop è stato chiamato così da Doug Cutting in onore di un elefante giocattolo appartenente a suo figlio.)
Apache Hadoop: un'implementazione open source di MapReduce
![]()
Hadoop è stato accolto con grande popolarità e presto gli sviluppatori hanno iniziato a introdurre astrazioni per descrivere i lavori a un livello superiore. Laddove in precedenza le funzioni di input, mapper, combiner e reducer dei lavori venivano specificate in modo dettagliato (solitamente in Java semplice), ora gli utenti avevano la possibilità di creare pipeline di dati utilizzando fonti, destinazioni e operatori comuni con Cascading. Con Pig, gli sviluppatori potevano definire i lavori a un livello ancora più alto, utilizzando un nuovo linguaggio specifico per il dominio chiamato Pig Latin. Per un confronto, vedi il conteggio delle parole in Hadoop, Cascading (2007) e Pig (2008).
Apache Spark: un motore analitico unificato per l'elaborazione di dati su larga scala
Nel 2009 Matei Zaharia ha iniziato a lavorare su Spark presso l'UC Berkeley AMPLab. Il tuo team ha pubblicato nel 2010 Spark: Cluster Computing with Working Sets che descriveva un metodo per riutilizzare un set di dati di lavoro in più operazioni parallele, e ha rilasciato la prima versione pubblica nel marzo dello stesso anno. Un articolo successivo del 2012 intitolato Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing ha vinto il premio come Best Paper all'USENIX Symposium on Networked Systems Design and Implementation. Il documento descrive un nuovo approccio chiamato Resilient Distributed Datasets (RDD), che consente ai programmatori di sfruttare i calcoli in memoria per ottenere aumenti delle prestazioni di diversi ordini di grandezza negli algoritmi iterativi, come PageRank o machine learning, rispetto agli stessi tipi di lavori eseguiti su Hadoop.
Insieme ai miglioramenti delle prestazioni per gli algoritmi iterativi, un'altra importante innovazione introdotta da Spark è stata la capacità di eseguire query interattive. Spark ha sfruttato un interprete interattivo di Scala per consentire ai data scientist di interagire con il cluster ed eseguire esperimenti su grandi set di dati in modo molto più rapido rispetto all'approccio tradizionale, che prevedeva la compilazione e l'invio di un job Hadoop, con conseguenti tempi di attesa per i risultati.
Tuttavia, persisteva un problema: l'input di questi job Hadoop o Spark considerava solo dati provenienti da una fonte delimitata, senza tenere conto dei nuovi dati in arrivo durante l'esecuzione. Il job è indirizzato a una fonte di input, determina la scomposizione in parti parallelizzabili o attività, esegue le attività simultaneamente nel cluster e, infine, combina i risultati e memorizza l'output in una destinazione specifica. Questo funzionava benissimo per job come la generazione di indici PageRank o la regressione logistica, ma era lo strumento sbagliato per un'ampia gamma di altri job che devono operare su fonti di dati illimitate o in streaming, come l'analisi del flusso di clic o la prevenzione delle frodi.
Apache Kafka: una piattaforma di streaming distribuita
Nel 2010 il team di ingegneri di LinkedIn si stava impegnando a riprogettare le basi del popolare social network professionale [A Brief History of Kafka, LinkedIn's Messaging Platform]. Come molti siti web, LinkedIn è passato da un'architettura monolitica a una con microservizi interconnessi, ma l'adozione di una nuova architettura basata su una pipeline universale costruita su un registro di commit distribuito chiamato Kafka ha permesso a LinkedIn di affrontare la sfida di gestire i flussi di eventi quasi in tempo reale e su larga scala. Kafka è stato così chiamato dall'ingegnere principale di LinkedIn Jay Kreps perché era "un sistema ottimizzato per la scrittura" e Jay era un fan dell'opera di Franz Kafka.
La motivazione principale di Kafka su LinkedIn era quella di disaccoppiare i microservizi esistenti in modo che potessero evolversi più liberamente e indipendentemente. In precedenza, qualsiasi schema o protocollo utilizzato per abilitare la comunicazione tra servizi aveva vincolato la coevoluzione dei servizi. Il team dell'infrastruttura di LinkedIn si è reso conto di aver bisogno di maggiore flessibilità per far evolvere i servizi in modo indipendente. Hanno progettato Kafka per facilitare la comunicazione tra i servizi in modo asincrono e basata sui messaggi. Doveva offrire durabilità (rendere persistenti i messaggi su disco), essere resiliente agli errori della rete e dei nodi, offrire caratteristiche quasi in tempo reale e scalare orizzontalmente per gestire la crescita. Kafka ha soddisfatto queste esigenze fornendo un registro distribuito (vedi The Log: What every software engineer should know about real-time data's unifying abstraction).
Nel 2011, Kafka è stato reso open source e molte aziende hanno iniziato ad adottarlo su larga scala. Kafka ha introdotto innovazioni rispetto alle precedenti astrazioni di code di messaggi o pub-sub, come RabbitMQ e HornetQ, in alcuni aspetti chiave:
- Gli argomenti Kafka (code) vengono partizionati per aumentare il numero di istanze in un cluster di nodi Kafka (denominati broker).
- Kafka utilizza ZooKeeper per il coordinamento dei cluster, l'elevata disponibilità e il failover.
- I messaggi vengono salvati in modo permanente su disco per periodi molto lunghi.
- I messaggi vengono consumati in ordine.
- I consumer mantengono il proprio stato per quanto riguarda l'offset dell'ultimo messaggio consumato.
Queste proprietà evitano ai produttori di dover mantenere lo stato di riconoscimento di ogni singolo messaggio. I messaggi potevano ora essere trasmessi al filesystem ad una velocità elevata. Poiché i consumer erano responsabili della gestione del proprio offset all'interno dell'argomento, potevano gestire aggiornamenti ed errori in modo più efficiente.
Apache Storm: sistema di calcolo distribuito in tempo reale
Nel frattempo, nel maggio del 2011, Nathan Marz stava firmando un accordo con Twitter per acquisire la sua azienda BackType. BackType era un'azienda che "costruiva prodotti di analisi per aiutare le aziende a comprendere il loro impatto sui social media sia storicamente che in tempo reale" [History of Apache Storm and Lessons Learned]. Uno dei fiori all'occhiello di BackType era un sistema di elaborazione in tempo reale soprannominato "Storm". Storm ha portato un'astrazione chiamata "topologia" in base alla quale le operazioni di flusso sono state semplificate in modo simile a quello che MapReduce aveva fatto per l'elaborazione in batch. Storm è diventato noto come "l'Hadoop del tempo reale" e ha raggiunto rapidamente la vetta di GitHub e Hacker News.
Apache Flink: calcoli stateful su flussi di dati
Flink ha fatto il suo debutto pubblico nel maggio 2011. Deve le sue radici a un progetto di ricerca chiamato "Stratosphere" [http://stratosphere.eu/], che è stato uno sforzo collaborativo tra una manciata di università tedesche. Stratosphere era stato progettato con l'obiettivo di "migliorare l'efficienza dell'elaborazione parallela di dati su piattaforme Infrastructure as a Service (IaaS)" [http://www.hpcc.unical.it/hpc2012/pdfs/kao.pdf].
Come Storm, Flink fornisce un modello di programmazione per descrivere i flussi di dati (chiamati "job" nel gergo di Flink) che includono una serie di flussi e trasformazioni. Flink include un motore di esecuzione per parallelizzare efficacemente il lavoro e pianificarlo su un cluster gestito. Una proprietà unica di Flink è che il modello di programmazione facilita sia le fonti di dati limitate che quelle illimitate. Ciò significa che la differenza di sintassi tra un job eseguito una sola volta che estrae i dati da un database SQL (quello che tradizionalmente potrebbe essere stato un processo batch) e un job eseguito in modo continuo che opera su dati in streaming da un argomento Kafka è minima. Flink è entrato a far parte del progetto di incubazione Apache nel marzo 2014 ed è stato accettato come progetto di alto livello nel dicembre 2014.
Nel febbraio del 2013 è stata rilasciata la versione alpha di Spark Streaming con Spark 0.7.0. Nel settembre del 2013, il team di LinkedIn ha reso open source il proprio framework di elaborazione degli stream "Samza" con questo post.
Nel maggio del 2014 è stato rilasciato Spark, 1.0.0 e ha incluso il debutto di Spark SQL. Sebbene la versione attuale di Spark all'epoca offrisse solo funzionalità di streaming, suddividendo una fonte di dati in "micro-batch", c'erano le basi per l'esecuzione di query SQL come applicazioni di streaming.
Apache Beam: un modello di programmazione unificato per processi batch e in streaming
Nel 2015 un gruppo di ingegneri di Google ha pubblicato un documento intitolato The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Nel 2014 è stata resa disponibile in commercio su Google Cloud Platform un'implementazione del modello Dataflow. L'SDK principale di questo lavoro, così come diversi connettori IO e un runner locale, sono stati donati ad Apache e sono diventati la versione iniziale di Apache Beam nel giugno 2016.
Uno dei pilastri del modello Dataflow (e Apache Beam) è che la rappresentazione della pipeline stessa viene astratta dalla scelta del motore di esecuzione. Al momento della stesura, Beam è in grado di compilare lo stesso codice della pipeline per indirizzare Flink, Spark, Samza, GearPump, Google Cloud Dataflow e Apex. In questo modo l'utente ha la possibilità di evolvere il motore di esecuzione in un secondo momento, senza alterare l'implementazione del lavoro. È disponibile anche un motore di esecuzione "Direct Runner" per il test e lo sviluppo in ambiente locale.
Nel 2016 il team Flink ha introdotto Flink SQL. Kafka SQL è stato annunciato nell'agosto 2017 e, nel maggio 2019, un gruppo di ingegneri di Apache Beam, Apache Calcite e Apache Flink ha presentato "One SQL to Rule Them All: An Efficient and Syntactically Idiomatic Approach to Management of Streams and Tables" verso un SQL di streaming unificato.
Dove siamo diretti
Gli strumenti a disposizione degli architetti del software che progettano la pipeline di dati continuano a evolversi a una velocità crescente. Stiamo vedendo motori di flusso di lavoro come Airflow e Prefect che integrano sistemi come Dask per consentire agli utenti di parallelizzare e programmare carichi di lavoro massicci di machine learning sul cluster. Concorrenti emergenti come Apache Pulsar e Pravega sono in competizione con Kafka per affrontare l'astrazione dello storage del flusso. Stiamo anche assistendo a progetti come Dagster, Kafka Connect e Siddhi che integrano componenti esistenti e forniscono nuovi approcci alla visualizzazione e alla progettazione della pipeline di dati. Il ritmo rapido dello sviluppo in questi settori rende questo periodo molto stimolante per la creazione di applicazioni ad alta intensità di dati.
Se pensi che lavorare con questo tipo di tecnologie per te sia interessante, ti invitiamo a contattarci! Stiamo assumendo in diversi ruoli tecnici e in più sedi.

Robert Boyd è Principal Software Engineer presso Barracuda Networks. La sua attuale area di interesse è l'archiviazione sicura e la ricerca di e-mail su larga scala.
I preferiti dei lettori del 2021
La fine dell'anno è sempre un ottimo momento per mostrare alcuni dei nostri contenuti preferiti. Questi sono i post del blog Barracuda più popolari del 2020. Speriamo che ti piacciano!
Ransomware e violazioni dei dati
- In che modo gli hacker utilizzano il phishing negli attacchi ransomware
- Le principali preoccupazioni delle organizzazioni sanitarie in merito al backup di Office 365
- Tre passaggi fondamentali per proteggersi dal ransomware
- L'attacco informatico di Colonial Pipeline rivela l'impatto economico del ransomware
Ricerca
- Tipi di minacce e-mail: phishing URL
- Threat Spotlight: tendenze del ransomware
- Threat Spotlight: attacchi esca
Report speciali
- Lo stato della sicurezza di rete nel 2021
- Lo stato della sicurezza delle applicazioni nel 2021
- Reti cloud: accelerazione verso il futuro
- Lo stato del backup di Office 365
- Approfondimenti sul numero crescente di attacchi automatizzati
Sotto la superficie
- Below the Surface: perché hai bisogno di una strategia di backup nativa nel cloud
- Below the Surface: promuovere le donne nella tecnologia
- Sotto la superficie: Secure Access Service Edge con Sinan Eren
Barracuda
- Barracuda è stata nominata Visionary nel Magic Quadrant
 2021 di Gartner® per i firewall di rete
2021 di Gartner® per i firewall di rete - Barracuda premiata da Comparably per la migliore cultura aziendale
- 3 entusiasmanti innovazioni di prodotto annunciate a Secured.21
- Dietro le quinte della collaborazione Barracuda e Microsoft su Cloud-to-Cloud Backup
- Barracuda inserita nella lista Security 100 del 2021 di CRN
- Barracuda vince il premio Best Customer Service agli SC Awards 2021
Domande ricorrenti
Alcune domande non spariscono mai. Perché non posso usare la mia e-mail personale per lavoro? Cosa vuol dire che questo spam non è spam? Questi post sono i preferiti dei lettori anno dopo anno.
- I rischi aziendali degli account e-mail personali
- Ham vs Spam: qual è la differenza
- Vettori di minacce: cosa sono e perché è necessario conoscerli?
Guardando al 2022
Avremo altri ottimi contenuti dai nostri esperti, tra cui Olesia, Tushar, Anastasia, Jonathan, Fleming e altri. Pubblichiamo più volte alla settimana e se desideri ricevere una notifica quando abbiamo nuovi contenuti, iscriviti al nostro blog per ricevere riepiloghi via e-mail degli ultimi post. I nuovi episodi di Below the Surface vengono trasmessi ogni poche settimane e puoi visualizzare gli episodi archiviati sul nostro sito web.
I migliori auguri per un felice anno nuovo, da parte di tutti noi di Barracuda.

Christine Barry è Senior Chief Blogger e Social Media Manager presso Barracuda. Prima di entrare a far parte di Barracuda, Christine ha lavorato per oltre 15 anni come field engineer e project manager per clienti K12 e SMB. Possiede diverse credenziali di tecnologia e di gestione dei progetti, un Bachelor of Arts e un Master of Business Administration. Si è laureata presso l'Università del Michigan.
Entra in contatto con Christine su LinkedIn qui.
Registrazione di eventi altamente scalabile su AWS
La maggior parte delle applicazioni genera eventi di configurazione ed eventi di accesso. È importante che gli amministratori abbiano visibilità su questi eventi. Barracuda Email Security Service offre trasparenza e visibilità su molti di questi eventi per aiutare gli amministratori a perfezionare e comprendere il sistema. Ad esempio, sapere chi ha effettuato l'accesso all'account e quando. Oppure sapere chi ha aggiunto, modificato o eliminato la configurazione di un determinato criterio.
Per creare questo sistema distribuito e ricercabile, sorgono molte domande, come:
- Come si dovrebbero scrivere questi log da tutte le applicazioni, i servizi e le macchine in una posizione centrale?
- Quale dovrebbe essere il formato standard dei file di log?
- Per quanto tempo è necessario conservare questi log?
- Come si dovrebbero correlare gli eventi di applicazioni diverse?
- Come si fa a fornire un meccanismo di ricerca semplice e veloce tramite un'interfaccia utente per l'amministratore?
- Come si rendono disponibili questi log tramite un'API?
Quando si pensa a un motore di ricerca distribuito, la prima cosa che viene in mente è Elasticsearch. È altamente scalabile con ricerca quasi in tempo reale ed è disponibile come servizio completamente gestito in AWS. Quindi, il percorso è iniziato pensando di archiviare questi log degli eventi in Elasticsearch, con tutte le diverse applicazioni che inviavano i log a Elasticsearch utilizzando Kinesis Data Firehose.
Componenti coinvolti in questa architettura
- Kinesis Agent – Amazon Kinesis Agent è un'applicazione software Java autonoma che offre un modo semplice per raccogliere e inviare dati a Kinesis Data Firehose. L'agente monitora continuamente i file di log degli eventi sulle istanze Linux EC2 e li invia al flusso di distribuzione Kinesis Data Firehose configurato. L'agente gestisce la rotazione dei file, il checkpoint e la ripetizione dei tentativi in caso di errori. Fornisce tutti i tuoi dati in modo affidabile, tempestivo e semplice. Nota: se l'applicazione che deve scrivere su Kinesis Firehose è un container Fargate, avrai bisogno di un container Fluentd. Tuttavia, questo articolo si concentra sulle applicazioni in esecuzione su istanze Amazon EC2.
- Kinesis Data Firehose – Il metodo direct put di Amazon Kinesis Data Firehose può scrivere i dati in formato JSON in Elasticsearch. In questo modo non memorizza alcun dato sul flusso.
- S3 – Un bucket S3 può essere utilizzato per eseguire il backup di tutti i record o dei record che non vengono consegnati a Elasticsearch. I criteri del ciclo di vita possono anche essere impostati per l'archiviazione automatica dei log.
- Elasticsearch – Elasticsearch ospitato da Amazon. L'accesso a Kibana può essere abilitato per facilitare l'interrogazione e la ricerca nei log per qualsiasi scopo di debug.
- Curator – AWS consiglia di utilizzare Lambda e Curator per gestire gli indici e gli snapshot del cluster Elasticsearch. AWS ha maggiori dettagli ed esempi di implementazione che possono essere trovati qui
- Interfaccia API REST – Puoi creare un'API come astrazione per Elasticsearch, che si integra bene con l'interfaccia utente. Le architetture di microservizi basate su API si sono dimostrate le migliori sotto molti aspetti, come la sicurezza, la conformità e l'integrazione con altri servizi.
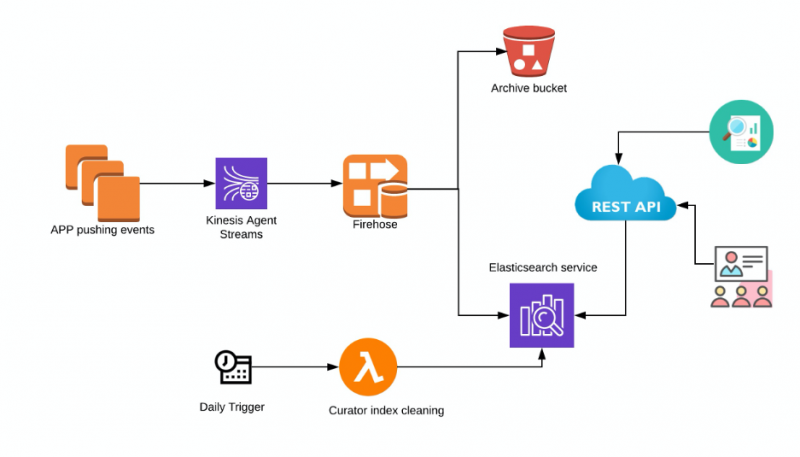
Scalabilità
- Kinesis Data Firehose: per impostazione predefinita, i flussi di consegna Firehose possono scalare fino a 1.000 record/s o 1 MiB/s per gli Stati Uniti orientali (Ohio). Si tratta di un limite flessibile che può essere aumentato fino a 10.000 record/s. Questo è specifico per regione.
- Elasticsearch: il cluster Elasticsearch può essere dimensionato sia in termini di storage che di potenza di calcolo su AWS. Sono possibili anche aggiornamenti di versione. Amazon ES utilizza un processo di distribuzione blu/verde per l'aggiornamento dei domini. Ciò significa che il numero di nodi nel cluster potrebbe aumentare temporaneamente durante l'applicazione delle modifiche.
Vantaggi di questa architettura
- L'architettura della pipeline è gestita in modo completo ed efficacemente e richiede pochissima manutenzione.
- Se il cluster Elasticsearch si guasta, Kinesis Firehose può conservare i record per un massimo di 24 ore. Inoltre, i record che non riescono a essere consegnati vengono sottoposti a backup su S3.
Con queste opzioni disponibili, le possibilità di perdita di dati sono basse.
- Il controllo granulare degli accessi è possibile sia per Kibana che per l'API Elasticsearch tramite i criteri IAM.
Difetti
- I prezzi devono essere attentamente considerati e monitorati. Kinesis Data Firehose è in grado di gestire grandi quantità di dati inseriti con facilità e se un agente non autorizzato inizia a registrare grandi quantità di dati, Kinesis Data Firehose li consegnerà senza problemi. Ciò può comportare costi elevati.
- L'integrazione di Kinesis Data Firehose in Elasticsearch è supportata solo per i cluster Elasticsearch non VPC.
- Al momento Kinesis Data Firehose non è in grado di distribuire i log ai cluster Elasticsearch non ospitati da AWS. Se si desidera ospitare autonomamente i cluster Elasticsearch, questa configurazione non funzionerà.
Conclusione
Se sei alla ricerca di una soluzione completamente gestita e (per lo più) scalabile senza interventi, questa sarebbe una buona opzione da prendere in considerazione. Il backup automatico su S3 con criteri del ciclo di vita risolve facilmente anche il problema della conservazione e dell'archiviazione dei log.

Sravanthi Gottipati è responsabile di ingegneria della sicurezza e-mail presso Barracuda Networks. Puoi entrare in contatto con lei su LinkedIn qui.
DJANGO-EB-SQS: Un modo più semplice per le applicazioni Django di comunicare con AWS SQS
I servizi AWS come Amazon ECS, Amazon S3, Amazon Kinesis, Amazon SQS e Amazon RDS sono ampiamente utilizzati in tutto il mondo. Noi di Barracuda utilizziamo AWS Simple Queue Service (SQS) per gestire la messaggistica all'interno e tra i microservizi che abbiamo sviluppato sul framework Django.
AWS SQS è un servizio di accodamento messaggi in grado di "inviare, archiviare e ricevere messaggi tra componenti software a qualsiasi volume, senza perdere messaggi o richiedere la disponibilità di altri servizi". SQS è progettato per aiutare le organizzazioni a disaccoppiare le applicazioni e scalare i servizi ed è stato lo strumento perfetto per il nostro lavoro sui microservizi. Tuttavia, ogni nuovo microservizio basato su Django o il disaccoppiamento di un servizio esistente utilizzando AWS SQS richiedeva la duplicazione del codice e della logica per comunicare con AWS SQS. Ciò ha comportato la ripetizione di un sacco di codice e ha incoraggiato il nostro team a creare questa libreria GitHub: DJANGO-EB-SQS
Django-EB-SQS è una libreria python pensata per aiutare gli sviluppatori a integrare rapidamente AWS SQS con applicazioni, nuove e/o esistenti, basate su Django. La libreria svolge i seguenti compiti:
- Serializzazione dei dati
- Aggiunta della logica di ritardo
- Polling continuo dalla coda
- Deserializzazione dei dati secondo gli standard AWS SQS e/o utilizzo di librerie di terze parti per comunicare con AWS SQS.
In breve, estrae tutta la complessità coinvolta nella comunicazione con AWS SQS e consente agli sviluppatori di concentrarsi solo sulla logica di business principale.
La libreria si basa sul framework Django ORM e la libreria boto3.
Come la usiamo
Il nostro team lavora a una soluzione di protezione dell'e-mail che utilizza l'intelligenza artificiale per rilevare lo spear phishing e altri attacchi di social engineering. Ci integriamo con l'account Office 365 dei nostri clienti e riceviamo notifiche ogni volta che ricevono nuove e-mail. Uno dei compiti è determinare se la nuova e-mail è priva di frodi o meno. Alla ricezione di tali notifiche, uno dei nostri servizi (Figura 1: Servizio 1) comunica con Office 365 tramite l'API Graph e riceve tali e-mail. Per un'ulteriore elaborazione di tali e-mail e per renderle disponibili per altri servizi, esse vengono quindi inviate alla coda AWS SQS (Figura 1: queue_1).

Figura 1
Esaminiamo un semplice caso d'uso su come utilizziamo la libreria nelle nostre soluzioni. Uno dei nostri servizi (Figura 1: Servizio 2) è responsabile di estrarre le intestazioni e i set di caratteristiche dalle singole e-mail e di renderle disponibili per il consumo da parte di altri servizi.
Il servizio 2 è configurato per ascoltare queue_1 per recuperare i corpi delle e-mail non elaborati.
Supponiamo che il Servizio 2 esegua le seguenti azioni:
# consuma i messaggi e-mail dalla queue_1
…
# estrai le intestazioni e i set di caratteristiche dalle e-mail
…
# invia un'attività
process_message.delay(tenant_id=, email_id=, headers=, tenant_id=, feature_set=,...)
Questo metodo process_messagenon non verrà richiamato in modo sincrono, ma sarà messo in coda come attività e verrà eseguito quando uno dei worker lo raccoglierà. Il worker in questione potrebbe provenire dallo stesso servizio o da un servizio diverso. Il chiamante del metodo non deve preoccuparsi del comportamento sottostante e di come l'attività verrà eseguita.
Diamo un'occhiata a come il metodo process_message viene definito come attività.
from eb_sqs.decorators import task
@task(queue_name='queue_2′, max_retries=3)
def process_message(tenant_id: int, email_id: str, headers: List[dict], feature_set: List[dict], …) :
Prova:
# esegui alcune azioni utilizzando le intestazioni e i set di caratteristiche
# è anche possibile mettere in coda altre attività, se necessario
except(OperationalError, InterfaceError) as exc:
Prova:
process_message.retry()
except MaxRetriesReachedException:
logger.error(‘MaxRetries reached for Service2:process_message ex: {exc}')
Quando decoriamo il metodo con il decoratore di attività, ciò che accade a livello interno è che vengono aggiunti dati extra come il metodo chiamante, il metodo di destinazione, i suoi argomenti e alcuni metadati aggiuntivi prima che il messaggio venga serializzato e inviato alla coda AWS SQS. Quando il messaggio viene consumato dalla coda da uno dei worker, contiene tutte le informazioni necessarie per eseguire l'operazione: quale metodo chiamare, quali parametri passare e così via.
È anche possibile riprovare l'attività in caso di eccezione. Tuttavia, per evitare uno scenario di loop infinito, possiamo impostare un parametro opzionale max_retries, dove è possibile interrompere l'elaborazione dopo aver raggiunto il numero massimo di tentativi. Possiamo, quindi, registrare l'errore o inviare l'attività a una coda di messaggi non recapitabili per un'ulteriore analisi.
AWS SQS offre la possibilità di ritardare l'elaborazione del messaggio fino a 15 minuti. Possiamo aggiungere una funzionalità simile alla nostra attività passando il parametro delay:
process_message.delay(email_id=, headers=, …., delay=300) # ritardo di 5 min
L'esecuzione delle attività può essere ottenuta eseguendo il comando Django process_queue. Questo supporta l'ascolto di una o più code, la lettura delle code all'infinito e l'esecuzione delle attività man mano che arrivano:
python manage.py process_queue –queues
Abbiamo appena visto come questa libreria semplifica la comunicazione all'interno del servizio o tra i servizi tramite le code di AWS SQS.
Maggiori dettagli su come configurare la libreria con le impostazioni di Django e la capacità di ascoltare più code, la configurazione dello sviluppo e molte altre funzionalità sono disponibili qui.
Contribuire
Se desideri contribuire al progetto, fai riferimento qui: DJANGO-EB-SQS

Rohan Patil è Principal Software Engineer presso Barracuda Networks. Attualmente sta lavorando a Barracuda Sentinel, un sistema di protezione basata su IA contro il phishing e il furto di account. Negli ultimi cinque anni ha lavorato alle tecnologie cloud e negli ultimi dieci anni ha ricoperto vari ruoli nell'ambito dello sviluppo di software. Ha conseguito un Master in Informatica presso la California State University e una Laurea in Informatica a Mumbai, in India.
Utilizzo di GraphQL per API robuste e flessibili
La progettazione delle API è un'area in cui possono esserci molte controversie tra gli sviluppatori di applicazioni client e gli sviluppatori di backend. Le API REST ci hanno permesso di progettare server stateless e di accedere in modo strutturato alle risorse per oltre due decenni e continuano a servire il settore, principalmente grazie alla loro semplicità e alla curva di apprendimento moderata.
REST è stato sviluppato intorno all'anno 2000, quando le applicazioni client erano relativamente semplici e il ritmo di sviluppo non era così veloce come lo è oggi.
Con un approccio tradizionale basato su REST, la progettazione si baserebbe sul concetto di risorse gestite da un determinato server. Poi, si farebbe tipicamente affidamento su verbi HTTP come GET, POST, PATCH, DELETE per eseguire operazioni CRUD su tali risorse.
Dagli anni 2000 sono cambiate diverse cose:
- L'aumento dell'uso di applicazioni su singola pagina e di applicazioni mobili ha creato l'esigenza di un caricamento efficiente dei dati.
- Molte architetture backend sono passate da un modello monolitico a un'architettura a microservizi (µservice) per cicli di sviluppo più rapidi ed efficienti.
- Per le API è necessaria una varietà di client e consumatori. REST rende difficile la creazione di un'API che supporti più client, in quanto restituirebbe una struttura di dati fissa.
- Le aziende si aspettano di lanciare le funzionalità più rapidamente sul mercato. Se è necessario apportare una modifica sul lato client, spesso richiede una regolazione lato server con REST, con conseguente rallentamento dei cicli di sviluppo.
- Una maggiore attenzione all'esperienza utente spesso porta alla progettazione di visualizzazioni/widget che richiedono dati da più server di risorse API REST per il rendering.
GraphQL come alternativa a REST
GraphQL è un'alternativa moderna a REST che mira a risolvere diverse carenze e la sua architettura e i suoi strumenti sono costruiti per offrire soluzioni per le pratiche di sviluppo software contemporanee. Consente ai client di specificare esattamente quali dati sono necessari e consente di recuperare i dati da più risorse in un'unica richiesta. Funziona in modo più simile a RPC, con query denominate e mutazioni invece di azioni obbligatorie standard basate su HTTP. Questo approccio dà il controllo a chi di competenza: lo sviluppatore dell'API di backend specifica ciò che è possibile e il client/consumatore dell'API specifica ciò che è necessario.
Ecco un esempio di query GraphQL, che mi ha aperto gli occhi quando l'ho incontrata per la prima volta. Supponiamo di costruire un sito web di microblogging e che sia necessario eseguire una query per trovare 50 post recenti.
query recentPosts(count: 50, offset: 0) {
id
title
tags
content
author {
id
name
profile {
email
interests
}
}
}
La query GraphQL di cui sopra ha lo scopo di richiedere:
- Ultimi 50 post
- ID, titolo, tag e contenuto per ogni post del blog
- Informazioni sull'autore contenenti ID, nome e informazioni sul profilo.
Se dovessimo utilizzare un approccio API REST tradizionale, il client dovrebbe effettuare 51 richieste. Se i post e gli autori sono considerati risorse separate, si tratta di una richiesta per ottenere 50 post recenti e poi 50 richieste per ottenere informazioni sull'autore per ogni post. Se le informazioni sull'autore fossero incluse direttamente nei dettagli del post, allora si potrebbe fare tutto con una sola richiesta API REST. Ma nella maggior parte dei casi, quando modelliamo i nostri dati utilizzando le migliori pratiche di normalizzazione dei database relazionali, gestiamo le informazioni sull'autore in una tabella separata, e questo porta le informazioni sull'autore ad essere una risorsa API REST separata.
Ecco la parte interessante di GraphQL. Supponiamo che, in una visualizzazione mobile, non abbiamo spazio sullo schermo per mostrare sia il contenuto del post che le informazioni sul profilo dell'autore. La query potrebbe ora essere:
query recentPosts(count: 50, offset: 0) {
id
title
tags
author {
id
name
}
}
Il client mobile ora specifica le informazioni che desidera e l'API GraphQL fornisce i dati esatti richiesti, niente di più e niente di meno. Non è stato necessario modificare il server, né il codice lato client ha subito cambiamenti significativi. Inoltre, il traffico di rete tra client e server è ottimale.
Il punto da notare qui è che GraphQL ci consente di progettare API flessibili in base ai requisiti lato client piuttosto che da una prospettiva di gestione delle risorse lato server. Una percezione generale è che GraphQL abbia senso solo per architetture complesse che coinvolgono diverse dozzine di microservizi. Questo è vero in una certa misura, dato che c'è una certa curva di apprendimento con GraphQL rispetto alle architetture API REST. Ma questo divario si sta colmando, con significativi investimenti intellettuali e finanziari da parte di una nuova fondazione vendor-neutral in rapida crescita.
Barracuda è uno dei primi ad adottare le architetture GraphQL. Se questo post ha suscitato il tuo interesse, segui questo spazio per i miei post successivi, dove approfondirò i dettagli tecnici e i vantaggi architettonici.

Vinay Patnana è responsabile di ingegneria del servizio di sicurezza e-mail presso Barracuda. In questo ruolo, assiste nella progettazione e nello sviluppo dei servizi di scalabilità delle soluzioni e-mail di Barracuda.
Vinay ha conseguito un Master in Informatica presso la North Carolina State University e una laurea in Ingegneria presso il BIT Mesra, in India. Lavora con Barracuda da diversi anni e vanta un'esperienza decennale di lavoro con diverse varietà di stack tecnici. Puoi entrare in contatto con lui su LinkedIn qui.
Nota: questo post è stato originariamente pubblicato sul blog aziendale di Databricks.
Il 74% delle organizzazioni a livello globale è stato vittima di un attacco di phishing. Barracuda Networks è un leader globale nelle soluzioni di sicurezza, distribuzione delle applicazioni e protezione dei dati, che aiuta i clienti a combattere gli attacchi di phishing su larga scala. Barracuda ha creato un potente motore di intelligenza artificiale che utilizza l'analisi comportamentale per rilevare gli attacchi e tenere a bada i malintenzionati.
Gestire le email di phishing è difficile a causa del livello di sofisticatezza con cui oggi gli hacker creano email dannose. Barracuda Networks utilizza l'apprendimento automatico per valutare e identificare i messaggi dannosi e proteggere i propri clienti. Grazie all'utilizzo dell'apprendimento automatico sulla piattaforma Databricks Lakehouse, il team di Barracuda è riuscito a muoversi molto più velocemente ed è adesso in grado di impedire a decine di migliaia di email dannose di raggiungere, ogni giorno, milioni di caselle di posta di migliaia di clienti.
Fornire una protezione completa per la sicurezza e-mail
Il team di Barracuda si dedica al rilevamento degli attacchi di phishing e alla sicurezza dei clienti. Raggiungono questo obiettivo lavorando su Microsoft Office 365 e analizzando il flusso di e-mail alla ricerca di eventuali minacce. Se viene rilevato un attacco, il messaggio viene immediatamente rimosso dalla casella di posta prima che gli utenti possano vederlo.
Protezione dal furto d'identità
Uno dei prodotti chiave offerti da Barracuda è la protezione dal furto d'identità. Il furto d'identità si verifica quando i malintenzionati mascherano i loro messaggi come se provenissero da una fonte ufficiale, come un dirigente o un servizio noto. Gli hacker possono utilizzare questo attacco per accedere a informazioni riservate, rappresentando un rischio significativo sia per gli individui che per le organizzazioni.
La protezione dal furto d'identità si concentra sulla dissuasione degli attacchi di phishing mirati. Tali tentativi non vengono inviati in grandi quantità, a differenza delle e-mail di spam. Per inviare un attacco mirato, l'hacker deve disporre di dettagli personali sul destinatario per personalizzarlo, come la sua professione o il campo di lavoro. Per identificare e bloccare gli attacchi di phishing e furto d'identità, il team ha dovuto creare un set di modelli di classificazione e distribuirli in produzione per gli utenti.
Difficoltà con il feature engineering
Per addestrare correttamente i nostri modelli IA a rilevare gli attacchi di phishing e di furto d'identità, Barracuda ha dovuto utilizzare i dati giusti e fare feature engineering su quei dati. I dati includevano il testo delle e-mail, che potrebbe essere un segnale di un attacco di phishing, e dati statistici, come i dettagli del mittente delle e-mail. Ad esempio, se un utente riceve un'email di fatturazione da qualcuno che non ha inviato un'e-mail simile negli ultimi mesi, questo potrebbe segnalare il rischio di un attacco di phishing. Prima dell'integrazione di Databricks, la creazione di funzionalità era più difficile con i dati etichettati distribuiti su più mesi, in particolare con le funzionalità statistiche. Inoltre, tenere traccia delle funzionalità quando il nostro set di dati cresceva di dimensioni era una sfida.
Implementazione lenta
Il nostro team ha tenuto il codice e il modello separati e ha dovuto duplicare il codice di ricerca per l'ambiente di produzione, il che ha richiesto tempo ed energia. Prima passavamo ogni e-mail in arrivo attraverso il codice di pre-elaborazione e poi inviavamo le e-mail pre-elaborate al modello per l'inferenza.
Barracuda ottiene successo utilizzando Databricks
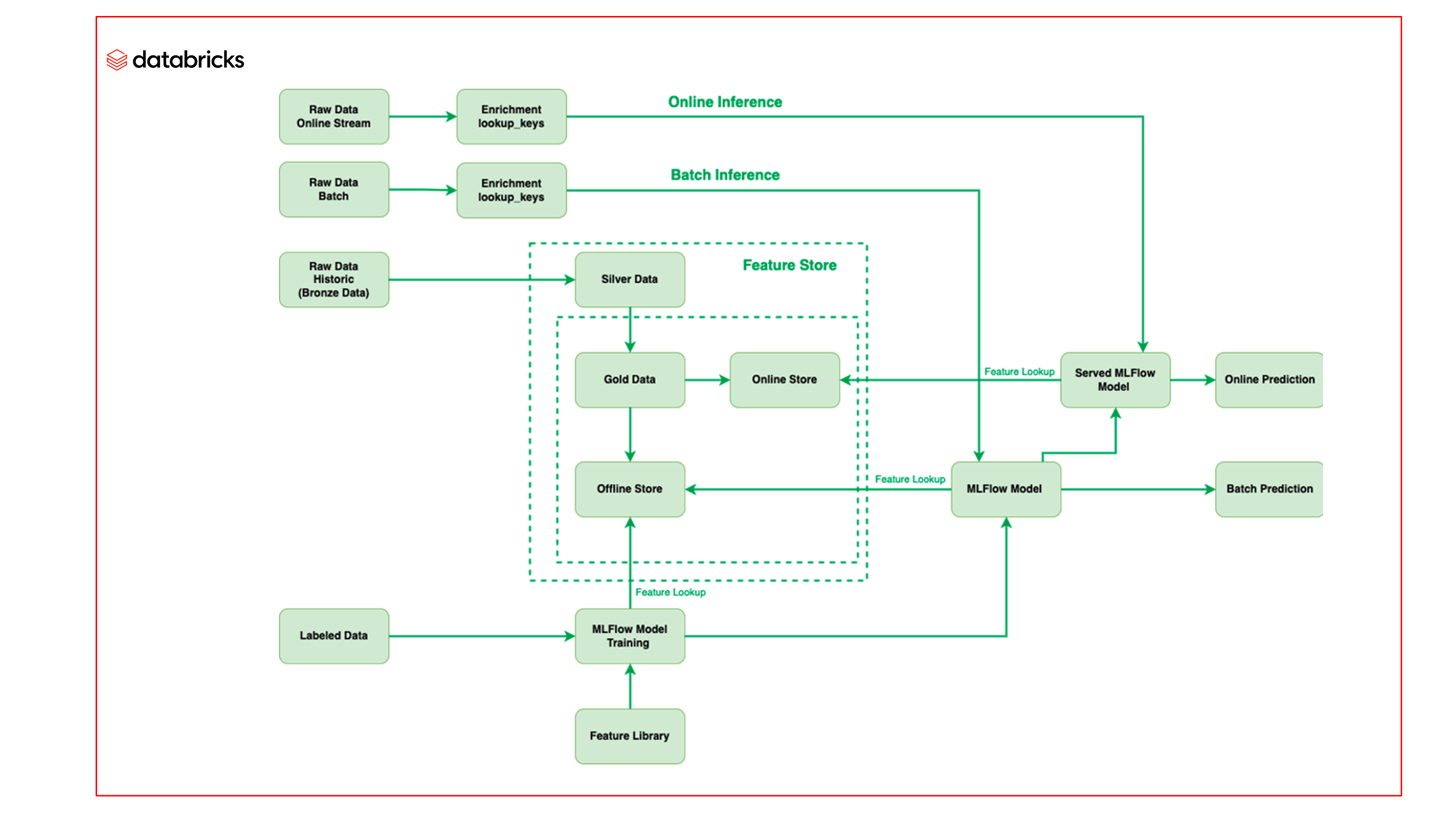
Il team di Barracuda ha sfruttato il machine learning sulla piattaforma Lakehouse di Databricks, in particolare utilizzando il Databricks Feature Store e Managed MLflow, per migliorare il processo di machine learning e distribuire più velocemente modelli di migliore qualità.

Feature Store
Il Databricks Feature Store funge da repository unico per tutte le funzionalità utilizzate dal team Barracuda. Per creare e gestire funzionalità statistiche costantemente aggiornate con nuovi batch di e-mail in arrivo, nel feature engineering sono stati utilizzati dati etichettati. Poiché il Feature Store è basato su Delta, non è richiesta alcuna elaborazione aggiuntiva per convertire i dati etichettati in funzionalità e le funzionalità rimangono aggiornate. Le funzionalità vengono conservate in un archivio offline e gli snapshot di queste informazioni vengono poi rilasciati online per essere utilizzati nell'inferenza online. Inoltre, integrando il Databricks Feature Store con MLflow, queste funzionalità possono essere facilmente richiamate dai modelli in MLflow e il modello può ottenere la funzionalità contemporaneamente al recupero della funzionalità quando arriva l'e-mail per l'inferenza.
Operazioni di machine learning più rapide
L'altro vantaggio è la gestione di tutti i modelli di machine learning in MLflow. Con MLflow, il team può spostare tutto il codice all'interno del modello, quindi può semplicemente far passare la posta attraverso il modello per l'inferenza invece di pre-elaborare il codice come si faceva prima. Questo rende il processo più semplice e più veloce nell'ottenere l'inferenza. Utilizzando MLflow, il team Barracuda è in grado di creare modelli completamente auto-confezionati. Questa funzionalità riduce notevolmente il tempo che il team dedica allo sviluppo di modelli ML.
Tasso di rilevamento più elevato
Con Databricks, il team ha più tempo e più calcoli, consentendo loro di pubblicare frequentemente una nuova tabella in Delta, aggiornare le funzionalità ogni giorno e usarle per capire se un'e-mail in arrivo è un attacco o meno. Ciò si traduce in una maggiore precisione nel rilevamento degli attacchi di phishing e migliora la protezione e la soddisfazione dei clienti.
Impatto
Con l'aiuto di Databricks, Barracuda protegge gli utenti dagli attacchi e-mail in tutto il mondo. Ogni giorno il team impedisce a decine di migliaia di e-mail dannose di raggiungere le caselle di posta dei clienti. Il team non vede l'ora di continuare a implementare nuove funzionalità di Databricks per migliorare ulteriormente l'esperienza dei nostri clienti.

{kind=link}
Mohamed Afifi Ibrahim è Principal Machine Learning Engineer presso Barracuda.